De Carrière Waarden Vragenlijst Adaptief (CW-A) is een adaptieve versie van de Carrière Waarden Vragenlijst Normatief (CWN), een persoonlijkheids- of drijfverenvragenlijst die in kaart brengt welke factoren van werk iemand motiveren.
Leeswijzer Carrière Waarden Vragenlijst Adaptief
Voor uw gemak hebben wij een leeswijzer opgesteld. Deze leeswijzer geeft een korte beschrijving en daarbij de belangrijkste conclusies van elk hoofdstuk. Zo krijgt u eenvoudig en snel inzicht in de informatie die relevant is voor het gebruik van de Carrière Waarden Vragenlijst Adaptief (CW-A).
De Carrière Waarden Vragenlijst Adaptief (CW-A) is een adaptieve versie van de Carrière Waarden Vragenlijst Normatief (CWN), een persoonlijkheids- of drijfverenvragenlijst die in kaart brengt welke factoren van werk iemand motiveren. Bij een adaptieve vragenlijst krijgt niet iedere kandidaat exact dezelfde lijst met vragen. Enkel de vragen die aanvullende informatie opleveren over de drijfveren van de kandidaat worden gesteld. Welke vragen gesteld worden, is afhankelijk van de antwoorden die de kandidaat heeft gegeven op eerder gestelde vragen. In de praktijk betekent dit dat vrijwel iedere kandidaat een andere vragenlijst krijgt. Als alle eigenschappen van de kandidaat betrouwbaar genoeg zijn gemeten, stopt de vragenlijst. De CW-A zorgt er dus voor dat kandidaten geen vragen krijgen die voor hen minder van toepassing zijn, dat wil zeggen, die weinig (nieuwe) informatie opleveren. Dit maakt de vragenlijst korter en minder herhalend, en daarmee minder belastend voor de kandidaat. In de volgende hoofdstukken geven we een toelichting over de ontwikkeling van de vragenlijst en presenteren we het onderzoek dat gedaan is naar deze vragenlijst.
1. Uitgangspunten bij de testconstructie
Voor de ontwikkeling van de adaptieve vragenlijst hebben we gebruik gemaakt van de vragen van de Carrière Waarden vragenlijst. Op basis van uitgebreid onderzoek hebben we voor elk van deze vragen vastgesteld welke informatie deze vraag oplevert voor verschillende drijfveren. Deze informatie wordt door het systeem gebruikt om de meest informatieve vragenlijst voor een kandidaat te genereren. Simpel gezegd gaat dat als volgt: op het moment dat een kandidaat een vragenlijst invult, selecteert het systeem uit een grote bak met vragen steeds de vraag die, na de vorige vraag, de meeste informatie oplevert. Dit gaat door totdat alle schalen voldoende nauwkeurig gemeten zijn. In dit hoofdstuk gaan we in op de voordelen van adaptief testen, gemiddeld levert de adaptieve wijze van bevragen al na 72 vragen voldoende informatie op om betrouwbare uitspraken te doen over de drijfveren van de kandidaat. In de praktijk betekent dit dat kandidaten een veel prettigere ervaring hebben bij het maken van de vragenlijst. Zij komen nauwelijks ‘dubbele’ vragen tegen die dezelfde kenmerken bevragen en zijn 3 keer sneller klaar met het invullen van de vragenlijst. Verder leest u in dit hoofdstuk meer over de multidimensionale itemrespons theorie, het statistische model dat gebruikt wordt bij adaptieve tests. Hierbij staan we ook uitgebreid stil bij de gemaakte keuzes en onderzoeken naar de itempool, de methode van itemselectie, de startregel en de stopregel van de adaptieve test.
De vragenlijst is gebaseerd op verschillende theoretische modellen, zoals de waarden van Schwartz (1999), de carrière-ankers van Schein (1993) en de behoeftepiramide van Maslow (1943), en bevat dezelfde items als de grondig gevalideerde en door de COTAN positief beoordeelde Carrière Waarden Vragenlijst Normatief (CWN) (zie ook de handleiding van de CWN). Er wordt een uitslag gegeven op 20 schalen. Deze 20 schalen en de clusters waar deze onder te plaatsen zijn, zijn als volgt gedefinieerd:




2. Betrouwbaarheid en validiteit
Uit onderzoek blijkt dat de betrouwbaarheden van de CW-A zeer hoog zijn (gemiddeld .87 voor de schalen). Daarnaast tonen analyses aan dat de uitslagen van de CW-A en de klassieke CWN sterk met elkaar samenhangen. Uit onderzoek blijkt dat de correlaties tussen de CW-A en CWN zeer hoog zijn (gemiddelde r = .92). en dat de factorstructuur overeenkomt. Op basis van deze hoge correlaties kunnen we concluderen dat de CWN en CW-A equivalent zijn. Deze onderzoeksresultaten ondersteunen de begripsvaliditeit en betrouwbaarheid van de CW-A.
3. Normgroepen
De normgroepen zijn gebaseerd op data verkregen in echte advies- (N = 8176) en selectiesituaties (N = 450), en zijn representatief voor de beroepsbevolking wat betreft geslacht, leeftijd en opleidingsniveau.
4. Handleiding voor testgebruikers
De CW-A kan toegepast worden bij alle vraagstukken waarbij inzicht in de persoonlijkheid van belang is, zowel in selectie- als adviessituaties. Omdat de afnameduur van deze vragenlijst erg kort is, is de toepassing zeer veelzijdig. U kunt denken aan selectieassessments, coaching en loopbaanadviessituaties.
Introductie
De Carrière Waarden Vragenlijst Adaptief, afgekort CW-A, is een drijfverenvragenlijst die voor het werkveld van Human Resource Management (HRM) is ontwikkeld door Ixly B.V. De CW-A is de adaptieve variant van de Carrière Waarden Vragenlijst Normatief (CWN), die in 2015 overwegend positief beoordeeld is door de Cotan. De CW-A is een persoonlijkheids- of drijfverenvragenlijst die in kaart brengt welke factoren van werk een persoon motiveren. De CW- A rapporteert op 20 schalen die onder drie thema’s vallen (Opbrengsten, Activiteiten en Omgeving). De CW-A kan zowel in advies- als in selectiesituaties ingezet worden. Bij adviessituaties geeft het rapport inzicht in de werkwaarden of carrièrewaarden die een persoon als motiverend ervaart. Hiermee kan er gericht gezocht worden naar een passende functie. In selectiesituaties kan gekeken worden of de werkwaarden van de persoon aansluiten bij de werkwaarden van het bedrijf en wat de functie qua werkwaarden kan bieden.
1. Uitgangspunten bij de testconstructie
De CW-A is een multidimensionale adaptieve persoonlijkheidsvragenlijst. Voor een uitgebreide beschrijving van hoe deze vragenlijsten precies werken verwijzen we u graag door naar de handleiding van de Adaptieve Persoonlijkheidsvragenlijst en naar het volgende achtergrondartikel.
1.1. Ontwikkeling van de CW-A
Een adaptieve test, zo ook de CW-A, bestaat uit een aantal vaste onderdelen:
-
Itempool met bekende itemparameters (sectie 1.1.1.)
-
Itemselectie (sectie 1.1.2.)
-
Startregel (het is gebruikelijk om bij adaptieve testen uit te gaan van een gemiddelde score, dus θ = 0. Deze regel hanteren we ook bij de CW-A)
-
Stopregel (sectie 1.1.3.)
De methode van de θ-schatting is feitelijk ook een onderdeel van een adaptieve test, maar deze is in de voorgaande sectie al besproken (de multidimensionale variant van de MAP-methode). In dit hoofdstuk wordt de ontwikkeling van en de gemaakte keuzes voor elk onderdeel van de eerste versie van de CW-A kort beschreven.
1.1.1. Itempool
1.1.1.1. Eerste kalibratie
Iedere adaptieve test of vragenlijst begint met een itempool, dus een verzameling vragen die getoond kunnen worden aan de kandidaat. Bij de CW-A vormden de items van de reguliere CWN de itempool; hier moesten echter wel nog de itemparameters voor berekend worden. Deze werden bepaald middels een een kalibratieonderzoek, wat hieronder besproken wordt.
De CWN wordt ingezet in zowel advies- als selectiesituaties. Bij de ontwikkeling van de CW-A was dan ook het doel dat deze bruikbaar zou zijn voor beide testsituaties. In eerste instantie is begonnen met de ontwikkeling van de CW-A voor adviesdoeleinden, waarna later gekeken is of de CW-A ook inzetbaar zou zijn in selectiesituaties. De onderzoeken tot en met sectie 3.1. zijn dus allen gebaseerd op data verkregen in adviessituaties.
Voor de eerste kalibratie is gebruik gemaakt van de Ixly database waar de behaalde scores zijn opgehaald van kandidaten die de CWN hadden ingevuld tussen 29 mei 2008 en 20 juni 2018. Het ging hier om kandidaten die de CWN daadwerkelijk in adviessituaties hadden ingevuld; de kalibratie en onderzoeken zijn dus gebaseerd op personen die de vragenlijst gemaakt hebben onder dezelfde condities als waar de vragenlijst uiteindelijk voor dient. In totaal konden we van 14221 personen gegevens achterhalen over het geslacht, leeftijd en opleidingsniveau. Deze informatie is weergegeven in Tabel 1.1.
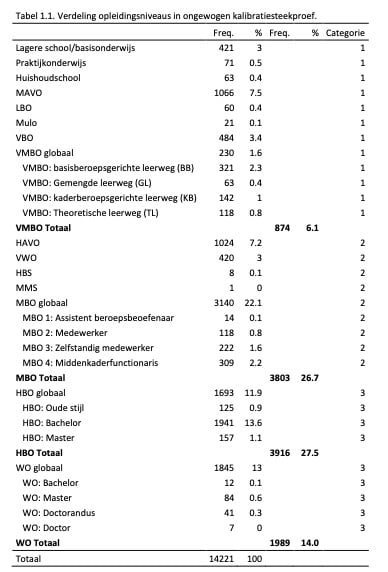
Tijdens de periode van dataverzameling is een aantal keer de bevraging van de achtergrondkenmerken veranderd; zo werd eerst bijvoorbeeld meer algemeen naar de categorieën VMBO, MBO, HBO en WO gevraagd, terwijl dit later fijnmaziger werd bevraagd met specifiekere opleidingsniveaus (bijv. MBO 1). Vandaar dat deze algemenere groepen (‘globaal’ in Tabel 1.1.) en specifiekere groepen weer zijn gegeven in Tabel 1.1.
Uiteindelijk zijn deze groepen gecombineerd in drie categorieën die zo goed mogelijk de categorieën van het CBS weerspiegelen. Deze categorieën zijn weergegeven in de uiterst rechter kolom. De verdeling in opleidingsniveaus over deze drie categorieën is weergegeven in Tabel 1.2.
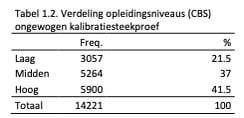
De verdeling wat betreft geslacht en leeftijd in de ongewogen kalibratiestreekproef is weergegeven in Tabel 1.3.
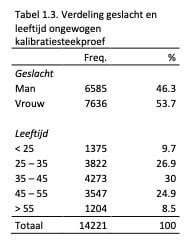
De representativiteit van deze steekproef wat betreft geslacht, leeftijd en opleidingsniveau is vergeleken met de verdeling van deze drie achtergrondkenmerken in de Nederlandse beroepsbevolking in 2017 volgens de gegevens van het CBS. Zoals in Tabel 1.4. te zien is, bleek dat er een significant verschil bestaat tussen de steekproef en de CBS data, op elk van de achtergrondvariabelen. Echter, uit inspectie van de φ effectgrootte (Tabel 1.4.) bleek dat deze verschillen voor geslacht en opleiding als ‘klein’ te bestempelen waren, en voor leeftijd als ‘gemiddeld’ (Cohen, 1988).
1.1.1.2. Gewogen steekproef
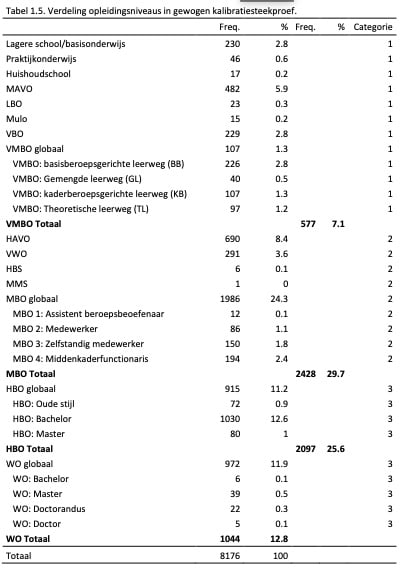
Om te corrigeren voor de verschillen tussen onze steekproef en de Nederlandse beroepsbevolking is er een wegingsprocedure uitgevoerd. Allereerst zijn er 2 (geslacht) x 5 (leeftijd) x 3 (opleiding) = 30 strata gecreëerd, waarna uit deze strata willekeurig een aantal personen werden getrokken met als doel (1) de verdeling wat betreft achtergrondkenmerken van het CBS zoveel mogelijk te benaderen en (2) een zo groot mogelijke steekproef te behouden. Uiteindelijk bleek dat deze twee doelen bij een steekproef van 8176 het best behaald werden. Na weging was er geen verschil in verdeling wat betreft geslacht tussen de gewogen steekproef en het CBS (χ2(1) = .00, p = .95). Er waren slechts kleine tot gemiddelde verschillen voor leeftijd (χ2(4) = 1.52, p = .82) en opleiding (χ2(2) = .53, p = .77). De verdeling wat betreft geslacht, leeftijd en opleidingsniveau in de gewogen Adviesnormgroep is weergegeven in Tabel 1.5.
Net als voor de ongewogen steekproef geldt dat tijdens de periode van dataverzameling de bevraging van de achtergrondkenmerken veranderd is; zo werd eerst bijvoorbeeld meer algemeen naar de categorieën VMBO, MBO, HBO en WO gevraagd, terwijl dit later fijnmaziger werd bevraagd met specifiekere opleidingsniveaus (bijv. MBO 1). Vandaar dat deze meeralgemenere groepen (‘globaal’ in Tabel 1.5) en specifiekere groepen weer zijn gegeven in Tabel 1.5.
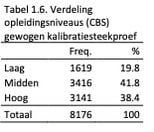
Uiteindelijk zijn deze groepen gecombineerd in drie categorieën die zo goed mogelijk de categorieën van het CBS weerspiegelen. Deze categorieën zijn weergegeven in de uiterst rechter kolom. De verdeling in opleidingsniveaus over deze drie categorieën is weergegeven in Tabel 1.6.
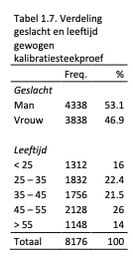
De verdeling wat betreft geslacht en leeftijd in de gewogen Adviesnormgroep is weergegeven in Tabel 1.7.
Helaas is er in de itemresponstheorie literatuur – en zeker in de literatuur over multidimensionale IRT – geen eenduidige richtlijn wat betreft de minimale steekproefgrootte voor een accurate schatting van de itemparameters (de kalibratie). Uit recent onderzoek dat specifiek op dit onderwerp focuste, is gebleken dat een steekgroep van N = 1000 een nauwkeurige schatting van itemparameters oplevert, en dat grotere steekproeven niet tot betere schattingen leiden; echter, dit onderzoek ging uit van slechts drie gecorreleerde schalen (Jiang, Wang & Weiss, 2016). In de CW-A hanteren we maar liefst 25 gecorreleerde schalen; het is dus lastig de resultaten van dit onderzoek naar onze situatie te generaliseren. Door onze steekproefgrootte van N = 8176 te hanteren weten we in ieder geval dat we ruim boven de bovengrens van N = 1000 uit dit artikel zitten.
1.1.1.3. Standaardfouten van itemparameters bij verschillende kalibratiesteekproeven
Om de invloed van de grootte van de kalibratiesteekproef te onderzoeken hebben we gekeken naar de grootte van de standaardfouten van de geschatte itemparameters in beide kalibraties; hoe kleiner de standaardfout, hoe nauwkeuriger de schatting van de itemparameter. De gemiddelde itemparameters en standaardfouten zijn weergegeven in Tabel 1.8.
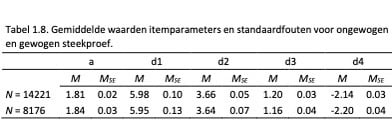
Uit Tabel 1.8. blijkt dat standaardfouten van de parameters kleiner zijn bij de grote, totale steekproef. In absolute zin is het verschil bij de eerste drempelwaarde (d1) het grootst, maar relatief gezien is het verschil bij alle drempelwaardes ongeveer hetzelfde. Overigens valt op dat de gemiddelde waarden van de parameters zelf weinig verschillen tussen de steekproeven.
Uit bovenstaande analyse van de gemiddelde standaardfouten blijkt al dat bij de totale steekproef de itemparameters nauwkeuriger geschat worden dan bij de gewogen steekproef. Dit wordt nog duidelijker wanneer we kijken naar de maximale standaardfouten: voor de a-parameter was dit .05 (totaal) vs. .06 (gewogen), voor d1 .28 vs. .36, voor d2 .13 vs. .19, voor d3 .07 vs. .09 en voor d4 .09 vs. .13. Hoewel de verschillen niet heel groot zijn, hebben we op basis van deze analyses besloten de eerste kalibratie te doen op de totale steekproef.
De invloed hiervan op de theta-schattingen hebben we bekeken door voor beide kalibraties de geschatte thetas te vergelijken. In Tabel 1.9. zijn deze gemiddelde verschillen tussen de theta’s op basis van beide kalibraties weergegeven.
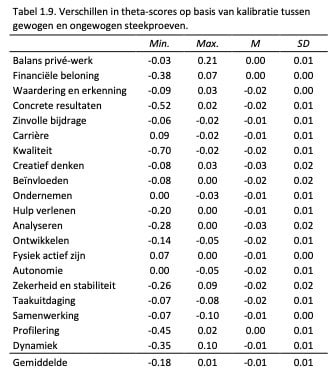
Uit Tabel 1.9. blijkt dat de theta-waarden geschat op basis van de gehele steekproef en de gewogen steekproef nauwelijks van elkaar verschilden. Het gemiddelde verschil was slechts -.01. Dus, de keuze om de itemparameterschattingen op basis van de ongewogen steekproef te nemen in verband met de grotere nauwkeurigheid (kleinere standaardfouten), heeft uiteindelijk weinig invloed gehad op de geschatte theta’s.
1.1.2. Itemselectie
Net als bij de APV is er voor de itemselectie gekozen voor de D-optimaliteit methode met een weging zodat alle schalen evenveel aan bod komen. Zie de handleiding van de APV voor meer informatie.
1.1.3. Stopcriterium
Ook voor het stopcriterium van de vragenlijst hebben we vastgehouden aan de methoden zoals beschreven in de handleiding van de APV (zie sectie 1.4.4. van de handleiding van de APV).
2. CW-A V1: Betrouwbaarheid en validiteit
Bij de gewogen kalibratiesteekproef (N = 8176) is de eerste versie van de CW-A gesimuleerd, waarbij de adaptieve test ingericht werd met de specificaties zoals hiervoor beschreven: de startwaarden van de theta’s werden op 0 gezet, itemselectie op basis van D-optimaliteit, een stopcriterium van SEM < .44, gecombineerd met een limiet van maximaal 6 items per schaal. Op basis van deze simulatie kan de nauwkeurigheid en de validiteit van de adaptief afgenomen vragenlijst vergeleken worden met de volledige, traditionele vragenlijst (de CWN). In het vervolg wordt met de ‘traditionele test’ de volledige CWN (187 items) bedoeld.
2.1. Validiteit
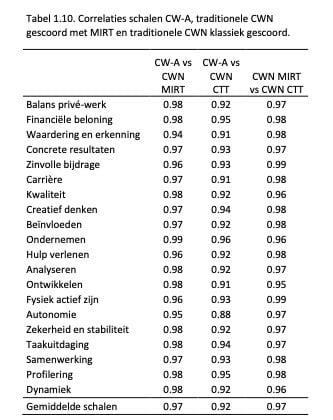
In Tabel 1.10. zijn de correlaties weergegeven van de theta’s verkregen met de adaptieve test en die verkregen na de traditionele versie van de test (dus gebruik makend van alle 187 items), gescoord met MIRT (kolom 2). Ook zijn de correlaties van de adaptief verkregen theta’s met de schaalscores (dus berekend volgens klassieke testtheorie) van de volledig afgenomen CW Normatief weergegeven (kolom 3). Ter vergelijking zijn in de laatste kolom de correlaties weergegeven tussen de klassiek gescoorde traditionele CWN en de traditionele CWN gescoord door middel van MIRT weergegeven.
Opvallend in Tabel 1.10. is dat alle correlaties zeer hoog zijn (> .88). De theta-scores op basis van de adaptieve test zijn vrijwel hetzelfde als de theta-scores verkregen op basis van de traditionele test (gemiddelde correlatie van .97 voor de schalen). Zelfs in vergelijking met de traditionele CWN, maar dan klassiek gescoord door middel van somscores van de schalen, is de rangordering van personen nagenoeg hetzelfde (gemiddelde correlatie van .92 voor de schalen). Dit is opvallend, omdat er in de adaptieve test slechts gemiddeld 72 items nodig waren om de theta’s te berekenen, vergeleken met 187 items van de traditionele CWN. Dit is een reductie van testtijd van ongeveer twee derde, terwijl dit dus weinig invloed heeft op de meting van de theta’s. Tot slot is het interessant om op te merken dat de twee scoremethoden (klassieke testtheorie vs. MIRT) bij de traditionele CWN nagenoeg dezelfde theta scores opleveren (laatste kolom).
Correlaties zeggen iets over de relatieve verhoudingen tussen variabelen, maar niet over absolute verschillen tussen de scores. Daarom hebben we in Tabel 1.11. de gemiddelde verschillen en de root mean square error (RMSE) weergegeven
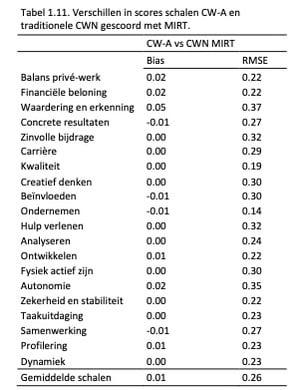
Uit zowel de gemiddelde verschillen als de RMSE-waarden blijkt dat de verschillen tussen de traditionele CWN en de adaptieve versie te verwaarlozen zijn. Dit betekent dat een persoon ongeveer dezelfde score zal behalen, ongeacht welke versie van de test ingevuld is.
2.2. Betrouwbaarheid
De resultaten zoals weergegeven in Tabel 1.10. en 1.11. geven al een indicatie dat met de adaptieve test de scores van de traditionele test goed benaderd kunnen worden. Dit zegt iets over de validiteit van de metingen, maar nog niet direct iets over de betrouwbaarheid: dus hoe nauwkeurig de metingen precies gedaan worden met de adaptieve vragenlijst. Om hier uitspraken over te doen zijn de betrouwbaarheden van de adaptieve en traditionele vragenlijst weergegeven: bij de adaptieve test en de traditionele vragenlijst gescoord met MIRT zijn dit de empirische betrouwbaarheden (Du Toit, 2003) en bij de klassiek gescoorde vragenlijst zijn dit Cronbach’s alfa waarden.
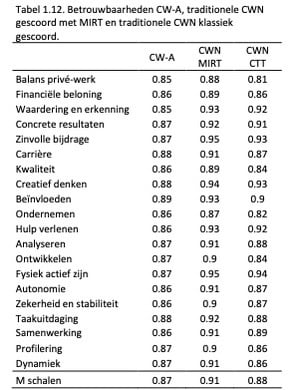
De conclusies op basis van Tabel 1.10. gelden ook voor Tabel 1.12.: hoewel de adaptieve vragenlijst iets aan betrouwbaarheid inlevert, is dit in vergelijking met de traditionele versie bijna te verwaarlozen. Zeker als er rekening wordt gehouden met de zeer korte afnameduur in vergelijking met de traditionele test. Dit betekent dat drijfveren met de adaptieve versie net zo nauwkeurig gemeten kunnen worden als met de traditionele versie van de CWN.
3. Normen
3.1. Eerste Adviesnormgroep
Bij de gewogen steekproef (zie pagina 11) is de eerste versie van de CW-A gesimuleerd, waarbij de adaptieve test ingericht werd met de specificaties zoals hiervoor beschreven: de startwaarden van de theta’s werden op 0 gezet, itemselectie op basis van D-optimaliteit, een stopcriterium van SEM < .44, gecombineerd met een limiet van maximaal 6 items per schaal.
Voor iedere persoon in de gewogen steekproef werd de CW-A gesimuleerd op basis van hun scores op de CWN. Nadat deze simulatie voltooid was, zijn de theta-scores genormeerd met de continue fit-methode (zie Van der Woud, 2008). Voor een uitgebreide uitleg over hoe van ruwe scores gekomen wordt tot stenscores verwijzen we naar de handleiding van de WPV Compact (Ixly, 2012, p. 50-55). De kenmerken van de ruwe scores en de stenscores (weergegeven in de rapportage van de CW-A) zijn beschreven in Tabel 1.13.
Met een asterisk (*) is aangegeven wanneer de Z-score (verkregen door de waardes door hun standaardfout te delen) van de scheefheid en kurtosis (platheid) de grens ± 2.58 overstijgt. Deze drempelwaarde wordt vaak gehanteerd als indicatie dat een verdeling van de theoretische normale verdeling afwijkt. Er zijn een aantal schalen waarbij de ruwe scores een wat schevere verdeling dan verwacht laten zien, en een aantal schalen waar de verdelingen een wat hogere piek laten zien dan verwacht. Als we naar de rechterkolommen kijken van Tabel 1.13. dan zien we dat deze afwijkingen van de normale verdeling grotendeels “weggenormeerd” zijn bij de (latente) stenscores van de CW-A.
3.2. Eerste Selectienormgroep
De CWN wordt ingezet in zowel advies- als selectiesituaties. Bij de ontwikkeling van de CW-A was dan ook het doel dat deze bruikbaar zou zijn voor beide testsituaties. Ten behoeve hiervan zijn twee belangrijke stappen ondernomen: eerst is onderzocht of de items hetzelfde functioneren wanneer kandidaten de vragenlijst in advies- of in selectiesituaties maken, om vervolgens een representatieve selectienormgroep te creëren. De onderzoeken die hiervoor gedaan zijn worden hieronder besproken.
Allereerst zijn de gegevens en scores opgehaald van kandidaten die de CWN daadwerkelijk in selectiesituaties hadden ingevuld. In totaal hadden we van 3316 personen gegevens over het geslacht, leeftijd en opleidingsniveau. De informatie wat betreft opleidingsniveau (in de drie eerder beschreven CBS categorieën) is weergegeven in Tabel 1.14.
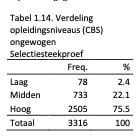
De verdeling wat betreft geslacht en leeftijd in de ongewogen Selectiesteekproef is weergegeven in Tabel 1.15.
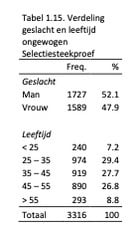
De representativiteit van deze steekproef wat betreft geslacht, leeftijd en opleidingsniveau is vergeleken met de verdeling van deze drie achtergrondkenmerken in de Nederlandse beroepsbevolking in 2017 volgens de gegevens van het CBS. Uit de Chi2-toetsen bleek dat er geen verschil in verdeling wat betreft geslacht was (χ2(1) = 0.95, p = .33), een gemiddeld tot groot verschil wat betreft leeftijd (χ2(4) = 375.49, p < .001, Cramer’s V = .17) en een groot verschil wat betreft opleidingsniveau (χ2(2) = 2008.59, p < .001, Cramer’s V = .55). Er bevonden zich in onze steekproef relatief minder mensen met een hogere leeftijd (> 55 jaar). In onze steekproef bevonden zich relatief veel hoger opgeleiden en minder middelbaar en lager opgeleiden.
3.3. Onderzoek naar differential item functioning (DIF) tussen Advies- en Selectiegroep
Wanneer scores van kandidaten verkregen worden via vragenlijsten is het belangrijk dat de vragenlijsten rechtvaardig (fair) zijn: rechtvaardig betekent dat geen onterechte vertekening (bias) ontstaat bij individuele uitkomsten en dat alleen reële verschillen tussen individuen zichtbaar worden in relatie tot de beroepspopulatie. Eén mogelijke veroorzaker van bias is de testsituatie waarin de kandidaat de vragenlijst maakt; het is bekend dat sollicitanten vaak wat sociaal wenselijker antwoorden om zo hun kans op de baan te vergroten. Hoewel we weten dat dit leidt tot (gemiddelde) verschillen tussen scores verkregen in selectiesituaties en andere situaties (bijv. onderzoek of adviessituaties; zie Birkeland, Manson, Kisamore, Brannick, & Smith, 2006), is niet geheel duidelijk in de literatuur wat het effect van de testsituatie op itembias is (zie bijv. O’Brien & LaHuis, 2011; Robie, Zickar, & Schmit, 2001; Stark, Chernyshenko, Chan, Lee, & Drasgow, 2001; Stark, Chernyshenko, & Drasgow, 2004).
Itembias houdt in dat personen uit de ene groep (bijvoorbeeld sollicitanten) op een andere manier reageren op een item of een item anders interpreteren dan een andere groep (bijvoorbeeld personen die een vragenlijst maken voor loopbaanontwikkeling). Om dit te onderzoeken hebben we een aantal DIF (differential item functioning, zie bijvoorbeeld Zumbo, 1999) analyses uitgevoerd: deze analyses toetsen de hypothese dat de scores op items tussen twee personen uit verschillende groepen niet significant van elkaar verschillen, wanneer de (latente) score op het construct dat dit item meet constant gehouden wordt. Met andere woorden, twee personen uit verschillende groepen (bijvoorbeeld een sollicitant en een loopbaan kandidaat) met dezelfde ‘ware’ mate van behoefte voor Zekerheid en Stabiliteit moeten dezelfde kans hebben op een bepaald gegeven antwoord (bijvoorbeeld ‘helemaal eens’).
3.3.1. DIF op basis van DFIT
De eerste methode die we gehanteerd hebben is de DFIT-methode (Raju, van der Linden, & Fleer, 1995). In deze methode worden de ‘ware’ scores op basis van itemparameters gekalibreerd op de referentiegroep (Advies) vergeleken met geschatte scores op basis van itemparameters gekalibreerd op de focale groep (Selectie). Hiervoor worden per item de volgende stappen ondernomen:
- Voor de focale groep worden de itemparameters geschat en vervolgens de theta-scores berekend
- Voor de referentiegroep worden de itemparameters geschat
- Vervolgens worden voor de theta’s verkregen bij (1) de voorspelde waarde op een item berekend op basis van de itemparameters verkregen bij (1) en voor de itemparameters verkregen bij (2)
- Vervolgens wordt het gemiddelde genomen van het gekwadrateerde verschil tussen de voorspelde waarden verkregen onder (3). Dit is de NCDIF-statistiek (Raju et al., 1995).
Wanneer itemkalibraties op twee verschillende steekproeven zijn gebaseerd, dan dienen de itemparameters op dezelfde schaal gezet te worden door middel van linking. In lijn met eerdere onderzoeken (O’Brien & LaHuis, 2011; Raju et al., 1995; Robie et al., 2001) hebben we de
adviesparameters gelinkt aan de parameters gekalibreerd op basis van de Selectiegroep. Dit is gedaan volgens de multidimensionale uitbreiding van de methode van Haebara (1980), met behulp van het plink pakket (Weeks, 2010) in R (R Core Team, 2017).
3.3.1.1. Resultaten DIF op basis van DFIT
Gezien de grootte van onze steekproeven hebben we niet gekeken naar de significantieniveaus van de NCDIF-waarden, maar naar de effectgrootten (ESSD; zie Meade, 2010); deze ESSD- waarden kunnen geïnterpreteerd worden als Cohen’s d-waarden. De gevonden effectgrootten en de interpretatie hierbij is weergegeven in Tabel 1.16.
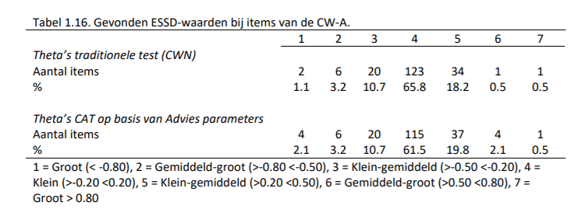
Allereerst hebben we gekeken naar de DIF-waarden bij de traditionele versie van de CWN (bovenste panel van Tabel 1.16). Uit deze analyses bleek dat de meerderheid van de items een geringe mate van DIF vertoonden. Het feit dat de meeste waarden positief zijn, komt overeen met de verwachting dat bij een gelijke ‘ware’ score op een bepaalde eigenschap, personen in een selectiesituatie een hogere kans hebben het eens te zijn met een antwoord omdat ze overal ‘een schepje bovenop doen’. Opvallend was echter wel dat bij iedere schaal er zowel positieve als negatieve DIF plaatsvond, dit betekent dat het niet altijd het geval was dat bij een gelijke score op een bepaalde eigenschap de kans op een positief antwoord altijd hoger was bij de Selectiegroep. Sollicitanten lijken dus niet ongeacht het item een hogere kans op een positief antwoord te hebben.
Slechts 1.6% van de items vertoonden grote mate van DIF. Om te onderzoeken in hoeverre de items die de meeste DIF lieten zien getoond werden in de CW-A (bij adaptieve tests worden immers niet alle items evenveel gebruikt, omdat sommige items informatiever zijn dan anderen), is gekeken naar de 20 items met de hoogste absolute ESSD-waarden. Hieruit bleek dat de meeste items procentueel gezien in weinig van de gevallen daadwerkelijk aan een kandidaat getoond werden (Mediaan = 8.2, SD = 35.0, Min. = .00, Max. = 100). Er waren echter ook een aantal items die vaak of zelfs altijd aan de kandidaat getoond werden. Dit waren echter alleen items met klein- gemiddelde en gemiddeld-grote mate van DIF. Bovendien worden er genoeg overige items gesteld om toch een goede schatting van de drijfveren van een persoon te schatten. Er waren bijvoorbeeld twee items van de schaal Ondernemen die een gemiddeld tot grote mate van DIF vertoonden die altijd getoond werden aan de kandidaat. Echter, de meeste mensen zullen 6 items van Ondernemen krijgen in de adaptieve vragenlijst (analyses toonden aan dat dit in 52% van de gevallen zo was), wat betekent dat er nog 4 “goede” items gesteld worden voor de schatting van de score op Ondernemen.
Overige analyses (hieronder beschreven) toonden dan ook aan dat deze effecten op itemniveau niet groot genoeg waren om van invloed te zijn op schaalniveau. Hieruit blijkt dat het effect van DIF in de praktijk bij de CW-A waarschijnlijk weinig invloed op de scores zal hebben.
Om hier nog beter inzicht in te krijgen is ook gekeken naar de DIF-waarden wanneer in de analyses de theta’s gebruikt werden uit de adaptieve (gesimuleerde) CW-A (onderste panel Tabel
1.16.). De resultaten kwamen sterk overeen met de resultaten op basis van de theta’s verkregen uit de traditionele CWN. In dit geval waren er iets meer (2.6%) items met een grote effectgrootte. Echter, ook nu bleek uit analyses dat de items met enige mate van DIF niet vaak genoeg getoond worden om van invloed te zijn op de schaalscores. Dit zal in de praktijk weer betekenen dat deze items weinig invloed zullen hebben op de scores van sollicanten die de CW-A invullen.
3.3.1.2. Resultaten DTF op basis van DFIT
Om hier nog meer inzicht in te krijgen is gekeken naar de invloed van de DIF items op de scores op schaalniveau (DTF). Ten behoeve daarvan zijn ook op schaalniveau de ESSD-waarden berekend (zie Tabel 1.17.). Hiervoor hebben we gebruik gemaakt van de theta’s verkregen via de adaptieve (gesimuleerde) vragenlijst. Afgaande op de richtlijnen van Cohen (1988) zien we dat alle schalen slechts een geringe mate van DTF vertonen. De schalen van de CW-A lijken zich dus niet anders te gedragen in selectiesituaties in vergelijking met adviessituaties. Deze analyses zijn overigens, net zoals de analyses op itemniveau, ook uitgevoerd op basis van de theta’s vergeleken uit de adaptief gesimuleerde CW-A bij de selectiekandidaten. De DTF-waarden waren nagenoeg gelijk en zijn daarom hier niet weergegeven.

3.3.2. Ordinale logistische regressie (OLR)
Omdat de statistische power van de verschillende methoden om DIF te detecteren verschilt, wordt aangeraden om meerdere methoden van onderzoek te gebruiken (Wood, 2011). We hebben daarom ook DIF en DTF onderzocht door middel van ordinale logistische regressie (OLR). Hiervoor hebben we het hiërarchische model van Zumbo (1999) gebruikt:
- Model 1: Eerst wordt een ordinale logistische regressie uitgevoerd met het item als de afhankelijke variabele en de totaalscore (theta) op het construct dat door dit item gemeten wordt als onafhankelijke variabele
- Model 2: Vervolgens wordt de groepsvariabele als onafhankelijke variabele ingevoerd (in ons geval Advies/Selectie).
- Model 3: Vervolgens wordt de interactie tussen de totaalscore en de groepsvariabele als onafhankelijke variabele ingevoerd.
Er zijn twee voorwaarden die bepalen wanneer we kunnen spreken van substantiële DIF. Allereerst kan de fit van deze modellen aan de hand van hun χ2 waarden vergeleken worden. Als de p-waarde van het verschil in χ2 waarden van Model 3 en Model 1 (met 2 vrijheidsgraden) kleiner is dan 0.01 (een α van 1% is hier nodig, omdat meerdere hypotheses getoetst worden; Zumbo, 1999), dan is Model 3 dus significant beter dan Model 1 en kan er sprake zijn van DIF.
In het voorgaande wordt aangegeven dat er ‘sprake kan zijn van DIF’: onder invloed van bijvoorbeeld de steekproefgrootte, relatieve grootte van de focale- en referentiegroep en de kenmerken van de items kan de χ2-waarde significant worden (Lei et al., 2006; Swaminathan & Rogers, 1990; Zumbo, 1999). De tweede voorwaarde is daarom dat er aanzienlijke effectgrootten moeten zijn voordat er sprake kan zijn van substantiële DIF (Kirk, 1996; Zumbo, 1999; Zumbo & Hubley, 1998). Hiervoor wordt het verschil in verklaarde variantie, ΔR2, tussen de verschillende modellen gebruikt. Jodoin en Gierl (2001) hanteren de categorieën: 0 – .035 als verwaarloosbaar, .035 – .07 als matig en >.07 als sterk. In het huidige onderzoek hanteren we deze vuistregel. Alleen wanneer aan de beide voorwaarden (significantie en een substantiële effectgrootte) voldaan wordt dan kunnen we spreken van substantiële DIF.
Bovenstaande test met 2 vrijheidsgraden kan gezien worden als een omnibus test voor zowel uniforme als non-uniforme DIF. Een manier om vervolgens inzicht te krijgen in de mate van uniforme- en non-uniforme DIF is door de R2-waarden van Model 2 en Model 3 te vergelijken. Het verschil in R2-waarden tussen Model 1 en Model 3 is namelijk additief (bijvoorbeeld ΔR2M3-M1 = .10): de ΔR2 tussen Model 1 en Model 2 is representatief voor uniforme DIF (bijvoorbeeld ΔR2M2- M1 = .08), de ΔR2 tussen Model 3 en Model 2 is representatief voor non-uniforme DIF (bijvoorbeeld ΔR2M3-M2 = .02).
Het effect van DIF op schaalniveau (DTF) kan ook onderzocht worden door:
-
voor ieder item de voorspelde score te berekenen op basis van het geschatte logistische model
-
voor iedere schaal de voorspelde schaalscore te berekenen door de scores verkregen onder (1) per schaal te sommeren en
-
deze voorspelde schaalscores in een grafiek af te zetten tegen de theta-scores, met aparte lijnen voor de Advies- en Selectiegroep.
Voordat we over konden gaan op onze analyses is eerst een gezamenlijke kalibratie uitgevoerd van de Advies- en Selectiegroep. Hiervoor werden deze twee groepen samengevoegd tot één steekproef (N = 17537), waarna eerst de itemparameters voor deze gecombineerde groep werden berekend en vervolgens de theta’s.
3.3.2.1. Resultaten DIF op basis van OLR
Uit de analyses bleek dat 149 van de 187 items (80%) potentiële DIF vertoonden op basis van het significantieniveau (M3 – M1). Echter, zoals vermeld dient ook gekeken te worden naar de effectgrootte. Hieruit bleek dat de maximaal gevonden effectgrootte slechts 0.035 was: deze maximale waarde ligt nog binnen de categorie tussen de 0 en 0.035 wat als ‘verwaarloosbaar’ gekenmerkt kan worden. Dit houdt in dat er op basis van deze analyses nauwelijks sprake van DIF op basis van testsituatie blijkt te zijn bij de items van de CW-A.
Bovenstaande analyses zijn echter gebaseerd op de antwoorden op de traditionele CWN en de theta’s geschat op basis van de traditionele CWN. Om te analyseren in hoeverre we DIF mogen verwachten bij de adaptieve versie van de CWN is de CW-A bij de Selectie normgroep (zie
hieronder) gesimuleerd, op basis van de itemparameters geschat bij de Advies groep. Vervolgens zijn de gegeven antwoorden uit de adaptieve versie, en de theta’s geschat op basis van deze antwoorden, gebruikt om de mate van DIF te analyseren. Door het adaptieve karakter van de vragenlijst werd niet ieder item door iedereen ingevuld, wat erin resulteerde dat de N per item sterk verschilde; bij items met een kleine N zou dit de resultaten kunnen beïnvloeden. Daarom hebben we alleen items onderzocht die in de adaptieve variant minstens 100 keer waren ingevuld; dit was bij 100 van de 187 items het geval. De resultaten bij deze analyses waren grotendeels vergelijkbaar met de resultaten op basis van de theta’s verkregen bij de traditonele CWN. Volgens de p-waarden waren er 78 van de 100 items aan te merken als potentiële DIF items. Echter, de effectgroottes wezen uit dat in de meerderheid van de items er sprake was van triviale DIF, namelijk bij 93 items. Twee items konden aangemerkt worden als items met veel DIF (>.07), en vijf items met een matige vorm van DIF (effectgrootte tussen de .035 en .07). De twee items met veel DIF waren getoond in 12% en 13% van de adaptief gesimuleerde tests; het effect van deze DIF-items op de behaalde scores zal in de praktijk dus meevallen (zie ook de volgende sectie). Wel zullen deze items actief in de gaten gehouden worden in de toekomst.
3.3.2.2. Resultaten DTF op basis van OLR
Voordat we de resultaten van de DTF analyses toelichten is het interessant om te vermelden dat er, zoals verwacht, verschillen in gemiddelde theta’s waren tussen Advies en Selectie. Deze verschillen waren in lijn met wat verwacht kan worden vanuit het oogpunt van sociaal wenselijk antwoorden. Zo antwoordden kandidaten in selectiesituaties dat ze meer gericht waren op werk (dan privé) ten opzichte van advies-kandidaten. Ook zeiden kandidaten in selectiesituaties minder waarde aan financiële beloningen te hechten in selectiesituaties, en juist meer waarde te hechten aan taakuitdaging.
De gemiddelde Cohen’s d waarde over de 20 schalen was -0.08 (SD = 0.31, Min. = -0.53, Max. = 0.71). Ook waren er verschillen in gemiddelde voorspelde schaalscores (gemiddelde Cohen’s d van -0.08). Echter, er bleken weinig verschillen wanneer de behaalde theta-score constant gehouden werd tussen de groepen; de geringe DIF effecten op itemniveau vertaalden zich dus door naar geringe effecten op schaalniveau.
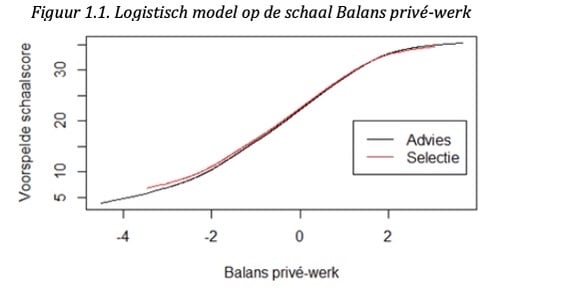
Een voorbeeld hiervan is te zien in Figuur 1.1., voor de schaal Balans privé-werk, waarvoor het verschil in gemiddelde (voorspelde) scores het grootst was (d = 0.70). Uit het figuur is af te lezen dat bij een gelijke score op Balans privé-werk (theta), de voorspelde score op basis van het logistische model nagenoeg hetzelfde is voor Advies en Selectie. Dus, hoewel er verschillen in gemiddelde scores zijn, lijken de schalen van de CW-A zich niet anders te gedragen in advies- en selectiesituaties.
3.3.3. Conclusie onderzoek DIF en DTF tussen Advies- en Selectiegroep
Op basis van twee verschillende methoden is onderzocht of de items van de CW-A anders functioneren wanneer deze onder adviessituaties ingevuld worden of onder selectiesituaties. Op basis van de methode van DFIT kwamen er enkele verschillen naar voren, hoewel deze (1) niet erg groot waren en (2) bij items voorkwamen die relatief weinig getoond worden in de CW-A. Op schaalniveau werden dan ook zeer kleine verschillen gevonden; dit was ook het geval wanneer de theta’s gebruikt werden die via de adaptief gesimuleerde CW-A verkregen waren.
Om de behaalde resultaten te verifiëren is ook via logistische regressie DIF en DTF onderzocht. Hieruit bleek dat er weinig tot geen sprake was van DIF of DTF; ook niet wanneer de adaptief gesimuleerde CW-A onderzocht werd. Uit de analyses bleek wel dat er verschillen in gemiddelde scores waren, in de richtingen die we zouden mogen verwachten als we er vanuit gaan dat in selectiesituaties sociaal wenselijker geantwoord wordt. Dit is een bekend gegeven uit de selectie- en assessment literatuur (Birkeland et al., 2006). De resultaten van beide methoden samen nemend is geconcludeerd dat de items niet anders functioneren onder de verschillende testsituaties; daarom is besloten de Selectiegroep simpelweg te scoren met de itemparameters gekalibreerd op de Adviesgroep, maar wel een Selectienormgroep te hanteren om voor vertekeningen in gemiddelde scores te corrigeren.
3.4. Ontwikkeling Selectienormgroep
Net als bij de Adviesnormgroep is er door middel van het trekken van een steekproef uit de ongewogen groep een representatieve normgroep wat betreft leeftijd, opleiding en geslacht gecreëerd. Bij een N van 450 was de balans tussen een zo groot mogelijke steekproef en een zo klein mogelijke afwijking van de CBS verdelingen wat betreft geslacht, leeftijd en opleiding optimaal. Na weging was er geen verschil in verdeling wat betreft geslacht (χ2(1) = .22, p = .64), leeftijd (χ2(4) = 1.61, p = .81) en opleidingsniveau (χ2(2) = 3.56, p = .17) tussen de gewogen steekproef en het CBS. De verdeling wat betreft geslacht, leeftijd en opleidingsniveau in de gewogen Selectienormgroep is weergegeven in Tabel 1.18. en 1.19.
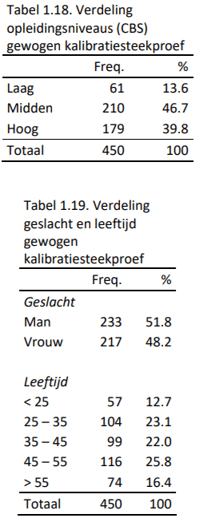
Net als bij de Adviesnormgroep is bij de Selectienormgroep de eerste versie van de CW-A gesimuleerd (zie pagina 16 voor de specificaties van de vragenlijst). Nadat iedere persoon in de normgroep de CW-A had doorlopen zijn de theta-scores genormeerd met de continue fit-methode (zie Van der Woud, 2007). De kenmerken van de ruwe scores en de stenscores (die weergegeven in de rapportage van de CW-A) zijn weergegeven in Tabel 1.20.
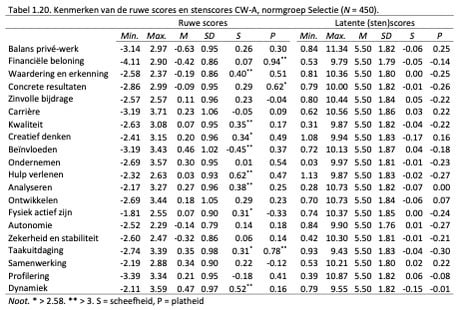
Met een asterisk (*) is aangegeven wanneer de Z-score (verkregen door de waardes door hun standaardfout te delen) van de scheefheid en kurtosis (platheid) de grens ± 2.58 overstijgt. Er zijn 9 schalen waarbij de ruwe scores een wat schevere verdeling dan verwacht laten zien, en 3 schalen waar de verdelingen een wat hogere piek laten zien dan verwacht. Echter, de vuistregel van ||Z||>2.58 wordt door sommigen als erg streng gekwalificeerd, en zij hanteren daarom liberalere regels waarbij absolute waarden van scheefheid > 3 en kurtosis > 8 (of zelf >10) gelden als een indicatie voor een afwijking van de normale verdeling (Kline, 2005). Gebaseerd op deze regels (zie Tabel 1.20.) kunnen we over het algemeen concluderen dat de ruwe scores van CW-A redelijk normaal verdeeld zijn in de normgroep. Bovendien zien we dat de stenscores niet afwijken van de normale verdeling wat betreft scheefheid en platheid.
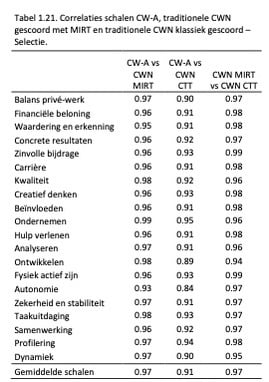
Net als bij de Adviesgroep is gekeken naar de samenhang tussen de theta-scores verkregen via de CW-A, de traditionele CWN gescoord via MIRT en gescoord volgens de klassieke testtheorie. De correlaties zijn weergegeven in Tabel 1.21. We zien, net als bij de Adviesgroep, dat de correlaties zeer hoog zijn. Als we de gemiddelde waarden onderin Tabel 1.21. vergelijken met Tabel 1.12., dan zien we nauwelijks verschillen; hieruit blijkt dat de CW-A zowel bij de Advies- als Selectiegroep sterke samenhang laat zien met de traditionele CWN en dat hier geen vertekeningen optreden door de testsituatie.
Ook zijn bij de Selectienormgroep de betrouwbaarheden berekend bij de adaptieve versie, de traditionele versie gescoord via MIRT en de klassiek gescoorde CWN. Deze zijn weergegeven in Tabel 1.22.
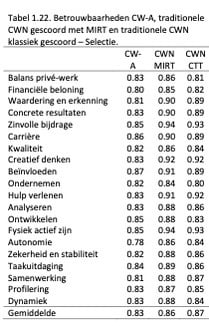
De betrouwbaarheden van de schalen zijn iets lager dan bij de Adviesgroep, maar nog steeds hoog.
Gemiddeld zijn er 70 items (SD = 9.0, Min. = 50, Max. = 111) nodig om tot deze betrouwbare
schattingen te komen; dit zijn gemiddeld 2 items minder dan bij Advies. Dit is een gemiddelde reductie van 63%. Qua afnametijd betekent dit dat de CW-A ook in selectiesituaties ongeveer 10 tot 15 minuten zal duren, vergeleken met 30 tot 40 minuten bij de traditionele CWN.
4. Handleiding voor testgebruikers
De CW-A is gebaseerd op de traditionele CWN. Inzet van het instrument en de rapportage zijn daarom vergelijkbaar. Om deze reden verwijzen we u naar de handleiding van de traditionele CWN.